Curiosidad impulsada por la IA: la curiosidad mató al gato, pero no a la máquina – Nonteek

IA curiosa: algoritmos impulsados por motivación intrínseca.
¿Qué significa IA impulsada por la curiosidad? La investigación y la innovación en IA están acostumbradas a que prácticamente todos los días surjan novedades y avances. Ahora estamos casi acostumbrados a algoritmos que pueden reconocer escenas y entornos en tiempo real y moverse en consecuencia, que pueden comprender el lenguaje natural (PNL), aprender el trabajo manual directamente a partir de la observación, «inventar» un vídeo con personajes conocidos para construir de nuevo imitaciones sincronizadas para audio, imitar la voz humana incluso en diálogos no triviales e incluso desarrollar nuevos algoritmos de IA por su cuenta (!).
La gente habla demasiado. Los humanos no descienden de los simios. Provienen de los loros. (La sombra del viento – Carlos Ruiz Zafón)
Todo muy bello e impresionante (o inquietante, según el punto de vista). Sin embargo, todavía faltaba algo: después de todo, incluso con la capacidad de mejorarse para lograr resultados comparables o incluso superiores a los de los humanos, todas estas actuaciones siempre partían del aporte humano. Es decir, siempre son los humanos quienes deciden probar suerte en una tarea particular, preparar los algoritmos y «empujar» la IA hacia una dirección particular. Después de todo, incluso los coches totalmente autónomos siempre necesitan tener un destino al que llegar. En otras palabras, no importa cuán perfecta o autónoma sea la ejecución: la motivación sigue siendo esencialmente humana.
No importa cuán perfecta o autónoma sea la ejecución: la motivación sigue siendo sustancialmente humana.
¿Qué es la «motivación»? Desde un punto de vista psicológico, es el «resorte» que nos empuja hacia una determinada conducta. Sin entrar en la multitud de teorías psicológicas al respecto (el artículo de Ryan y Deci puede ser un buen punto de partida para aquellos interesados, además de la entrada de Wikipedia), podemos distinguir genéricamente entre motivación extrínsecadonde el individuo está motivado por recompensas externas, y motivación intrínsecadonde el impulso a actuar proviene de formas de satisfacción interior.
:max_bytes(150000):strip_icc()/2795384-differences-between-extrinsic-and-intrinsic-motivation-5ae76997c5542e0039088559.png)
Estas «recompensas» o gratificaciones se denominan convencionalmente » refuerzos «, que pueden ser positivos (recompensas), o negativos (castigos), y son un poderoso mecanismo de aprendizaje, por lo que no es de extrañar que también haya sido explotado en Machine Learning.
Aprendizaje reforzado
AlphaGo de DeepMind fue el ejemplo más sorprendente de los resultados que se pueden lograr con el aprendizaje por refuerzo, e incluso antes de eso, el propio DeepMind había presentado resultados sorprendentes con un algoritmo que aprendió a jugar videojuegos por sí solo (el algoritmo no sabía casi nada sobre las reglas). y entorno del juego).
Sin embargo, este tipo de algoritmo requería una forma inmediata de aprendizaje por refuerzo: [right attempt] – [reward] – [more likely to repeat it] – [wrong attempt] – [punishment] – [less chance of falling back]. La máquina recibe información sobre el resultado (por ejemplo, la puntuación) al instante, por lo que es capaz de elaborar estrategias que conduzcan a la optimización hacia la mayor cantidad de «recompensas» posible. Esta situación se parece en cierto sentido al problema de los incentivos corporativos: son muy eficaces, pero no siempre en la dirección esperada (por ejemplo, el intento de proporcionar incentivos a los programadores con líneas de código, que resultó ser muy eficaz para fomentar la longitud del código, en lugar de calidad, que era la intención).

Sin embargo, en el mundo real los refuerzos externos suelen ser raros, o incluso ausentes, y en estos casos, la curiosidad puede funcionar como un reforzador intrínseco (motivación interna) para desencadenar la exploración del entorno y aprender habilidades que pueden resultar útiles más adelante.
El año pasado, un grupo de investigadores de la Universidad de Berkeley publicó un artículo notable, probablemente destinado a ampliar los límites del aprendizaje automático, cuyo título era Exploración impulsada por la curiosidad a partir de predicciones autosupervisadas. La curiosidad en este contexto se definió como «el error en la capacidad de un agente para predecir las consecuencias de sus propias acciones en un espacio de características visuales aprendidas de un modelo dinámico inverso autosupervisado». En otras palabras, el agente crea un modelo del entorno que explora, y el error en las predicciones (la diferencia entre el modelo y la realidad) consiste en el refuerzo intrínseco que fomenta la curiosidad de la exploración.
La investigación involucró tres escenarios diferentes:
- «Recompensa extrínseca escasa», o refuerzos extrínsecos entregados con baja frecuencia.
- Exploración sin refuerzos extrínsecos.
- Generalización de escenarios inexplorados (por ejemplo, nuevos niveles del juego), donde el conocimiento adquirido a partir de experiencias previas facilita una exploración más rápida que no comienza desde cero.
Como puede ver en el video de arriba, el agente con curiosidad innata puede completar el Nivel 1 de Super Mario Bros y VizDoom sin ningún problema, mientras que el que no lo tiene suele golpearse contra las paredes o quedarse atascado en un rincón.
Módulo de Curiosidad Intrínseca (ICM)
Lo que proponen los autores es el Módulo de Curiosidad Intrínseca (ICM), que utiliza la metodología de gradientes asíncronos A3C propuesta por Minh et al. para determinar las políticas a seguir.
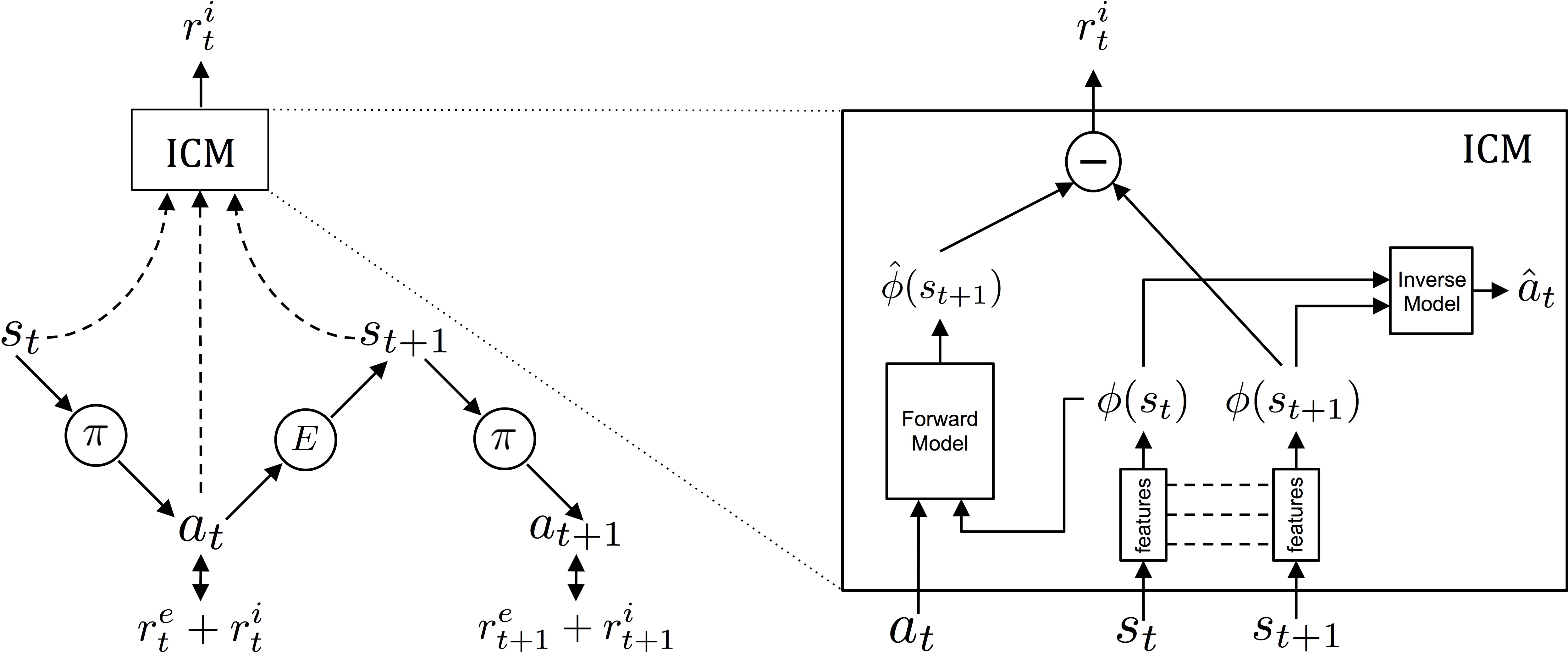
Arriba he presentado el diagrama conceptual del módulo: a la izquierda muestra cómo interactúa el agente con el entorno en relación con la política y los refuerzos que recibe. El agente se encuentra en un determinado estado. sty ejecutar la acción en de acuerdo al plan π. La acción αt eventualmente recibirá refuerzos intrínsecos y extrínsecos (rmit+rit) y modificará el medio ambiente mi conduce a un nuevo estado st+1… etcétera.
A la derecha hay una sección transversal de ICM: el primer módulo convierte los estados sin procesar st del agente en características φ(st) que se puede utilizar en el procesamiento. A continuación, el módulo de dinámica inversa (modelo inverso) utiliza las características de dos estados adyacentes φ(st) y φ (st+1) a predice la acción que realizó el agente para cambiar de un estado a otro.
Al mismo tiempo, también se entrena otro subsistema (modelo directo), que predice la siguiente característica a partir de la última acción del agente. Ambos sistemas están optimizados juntos, lo que significa que el modelo inverso aprende características que solo son relevantes para la predicción del agente, y el modelo directo aprende a hacer predicciones sobre estas características.
¿Entonces?
El punto clave es que, dado que no hay refuerzo para las características ambientales que son intrascendentes para las acciones del agente, la estrategia aprendida es robusta ante aspectos ambientales incontrolables (ver el ejemplo del ruido blanco en el video).
Para entendernos mejor, el verdadero refuerzo del agente aquí es la curiosidad, es decir, el error en la predicción de los estímulos ambientales: cuanto mayor sea la variabilidad, más errores cometerá el agente en la predicción del entorno, más mayor es el refuerzo intrínseco, que mantiene al agente «curioso».

La razón para extraer las características mencionadas anteriormente es que la predicción basada en píxeles no solo es muy difícil, sino que hace que el agente sea demasiado frágil al ruido o elementos que no son muy relevantes. Sólo para dar un ejemplo, si durante una exploración el agente se encuentra frente a árboles con hojas ondeadas por el viento, el agente corre el riesgo de fijarse en las hojas por la única razón de que son difíciles de predecir, descuidando todo lo demás. En cambio, ICM nos proporciona funciones extraídas de forma autónoma del sistema (básicamente autosupervisadas), lo que da como resultado la robustez de la que hablábamos.
Generalización
El modelo propuesto por los autores hace una contribución significativa a la investigación sobre exploración impulsada por la curiosidad, ya que el uso de características extraídas por sí mismas en lugar de predecir píxeles, hace que el sistema sea casi inmune al ruido y elementos irrelevantes, y evita entrar en callejones sin salida.

Sin embargo, eso no es todo: este sistema, de hecho, es capaz de utilizar los conocimientos adquiridos durante la exploración para mejorar el rendimiento. En la figura superior el agente logra completar el nivel 2 de SuperMario Bros mucho más rápido gracias a la «curiosa» exploración realizada en el nivel 1, mientras que en VizDoom pudo recorrer el laberinto muy rápidamente sin chocar contra las paredes.
En SuperMario el agente es capaz de completar el 30% del mapa sin ningún tipo de refuerzo extrínseco. La razón, sin embargo, es que al 38% hay un abismo que sólo puede superarse con una combinación bien definida de 15-20 claves: el agente cae y muere sin ningún tipo de información sobre la existencia de más porciones de lo explorable. . ambiente. El problema en sí no está relacionado con aprender con curiosidad, pero ciertamente es un obstáculo que debe resolverse.
Notas
La política de aprendizaje, que en este caso es el modelo Asynchronous Advantage Actor Critic (A3C) de Minh et al. El subsistema de políticas está capacitado para maximizar el refuerzo. rmit+rit (dónde rmit es cercano a cero).
Enlaces
Richard M. Ryan, Edward L. Deci: Motivaciones intrínsecas y extrínsecas: definiciones clásicas y nuevas direcciones. Psicología de la Educación Contemporánea 25, 54–67 (2000), doi:10.1006/ceps.1999.1020.
En busca de los fundamentos evolutivos de la motivación humana
D. Pathak y col. Exploración impulsada por la curiosidad con predicciones autosupervisadas. archivo 1705.05363
MÁQUINAS INTELIGENTES Aprende CÓMO SER CURIOSO (Y JUGAR A SUPER MARIO BROS.)
IM de Abril, R. Kanai: Aprendizaje por refuerzo impulsado por la curiosidad con regulación homeostática – arXiv 1801.07440
Los investigadores han creado una IA que es naturalmente curiosa
V. Mnih y otros: Métodos asincrónicos para el aprendizaje por refuerzo profundo – archivoXiv:1602.01783
Actor crítico de ventaja asincrónica (A3C) – Github (código fuente)
Métodos asincrónicos para el aprendizaje por refuerzo profundo: el periódico de la mañana
Hoja de referencia de AlphaGo Zero
Los 3 trucos que hicieron funcionar AlphaGo Zero
Andrea ha trabajado en TI durante casi 20 años, cubriendo todo, desde desarrollo hasta análisis de negocios y gestión de proyectos.
Hoy podemos decir que es un gnomo desenfadado, apasionado de las Neurociencias, la Inteligencia Artificial y la fotografía.
Related Posts
Aquí están las noticias de Android que te perdiste esta semana

La nueva colección Brännboll de Ikea es una adición bienvenida a mi desordenada configuración de juegos
