Los ligeros Gemma LLM de Google se hacen más pequeños, pero funcionan incluso mejor que antes

Google LLC está avanzando en sus esfuerzos en inteligencia artificial de código abierto con tres nuevas incorporaciones a su familia Gemma 2 de grandes modelos de lenguaje, que, según dijo, son notablemente «más pequeños, más seguros y más transparentes» que muchos de sus pares.
La compañía lanzó sus primeros modelos Gemma en febrero. Se diferencian de sus modelos insignia Gemini, que se utilizan en los productos y servicios propios de la empresa y, en general, se consideran más avanzados. Las principales diferencias son que los modelos Gemma son mucho más pequeños y completamente de código abierto, lo que significa que su uso es gratuito, mientras que los modelos de la familia Gemini son más grandes y de código cerrado, por lo que los desarrolladores tienen que pagar por el acceso.
Los modelos Gemma se basan en la misma investigación que los LLM de Gemini y representan el esfuerzo de Google para fomentar la buena voluntad en la comunidad de IA, de manera similar a como Meta Platforms Inc. ella está haciendo lo mismo con sus modelos Llama.
De los tres nuevos modelos anunciados hoy, el más importante es Gemma 2 2B, que es un LLM liviano diseñado para generar y analizar texto. Según Google, está diseñado para ejecutarse en dispositivos locales, como computadoras portátiles y teléfonos inteligentes, y tiene licencia para su uso en aplicaciones comerciales y de investigación.
Aunque Gemma 2 2B contiene sólo 2.600 millones de parámetros, Google dijo que muestra un rendimiento que está a la par, y a veces incluso superior, a sus homólogos mucho más grandes, incluidos el GPT-3.5 de OpenAI y el Mistral 8x7B de Mistral AI.
Para respaldar sus afirmaciones, Google publicó los resultados de pruebas independientes realizadas por LMSYS, una organización de investigación de IA. Según LMSYS, Gemma 2 2B obtuvo una puntuación de 1.126 en su área de evaluación de chatbot, superando a Mixtral-8x7B, que obtuvo una puntuación de 1.114, y a GPT-3.5-Turbo-0314, que obtuvo una puntuación de 1.106. Los resultados son impresionantes, ya que los últimos modelos tienen casi 10 veces más parámetros que la última edición de Gemma.
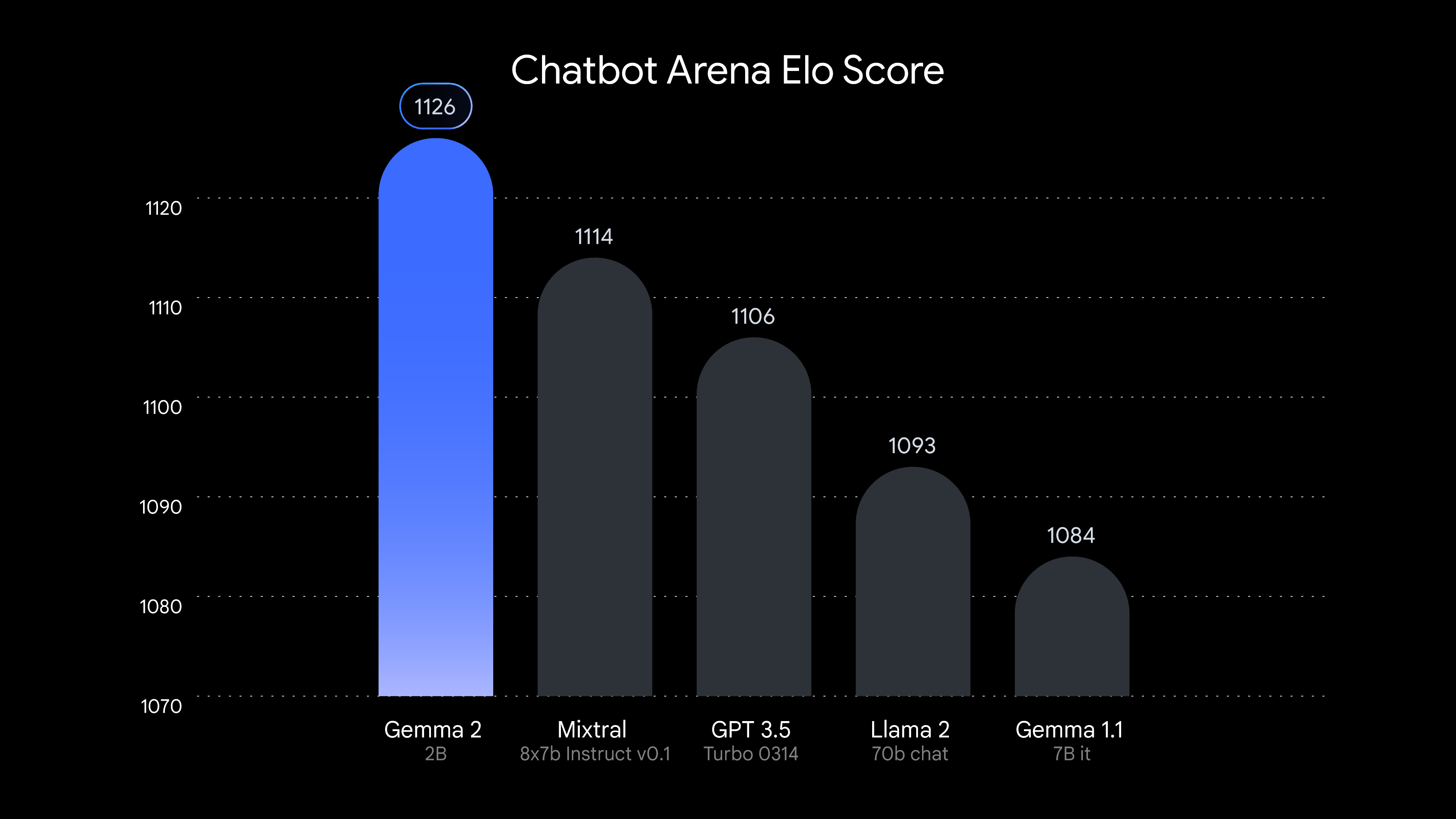
Google dijo que las capacidades de Gemma 2 2B van más allá de la eficiencia del tamaño. Obtuvo una puntuación de 56,1 en el punto de referencia de comprensión masiva del lenguaje multitarea y de 36,6 en la prueba de programación Python mayoritariamente básica, una mejora con respecto a la puntuación de los modelos Gemma anteriores.
Los resultados desafían la idea en IA de que un tamaño de parámetro mayor equivale a un mejor rendimiento. En cambio, Gemma 2 2B muestra que al utilizar técnicas de entrenamiento más sofisticadas y arquitecturas superiores y datos de entrenamiento de mayor calidad, es posible compensar una menor cantidad de parámetros.
Google dijo que su trabajo podría ayudar a iniciar un cambio en las empresas de inteligencia artificial, lejos de centrarse en la construcción de modelos cada vez más grandes. En cambio, podría llevar a los modeladores de IA a centrarse más en perfeccionar los modelos existentes para que funcionen mejor.
Además, Google dijo que Gemma 2 2B también muestra la importancia de utilizar técnicas de compresión y destilación del modelo. La empresa explicó que Gemma 2 2B se desarrolló extrayendo conocimientos de modelos mucho más grandes. Espera que el progreso en esta área permita el desarrollo de una IA más accesible con requisitos de potencia computacional reducidos.
Los otros modelos más especializados anunciados hoy por Google incluyen ShieldGemma, que en realidad es una colección de clasificadores de seguridad diseñados para detectar respuestas tóxicas como discursos de odio, acoso y contenido sexual explícito. ShieldGemma se basa en el modelo Gemma 2 original y los desarrolladores pueden utilizarlo para filtrar mensajes maliciosos que alientan a los modelos a responder de forma no deseada. También se puede utilizar para filtrar las respuestas reales de los LLM.
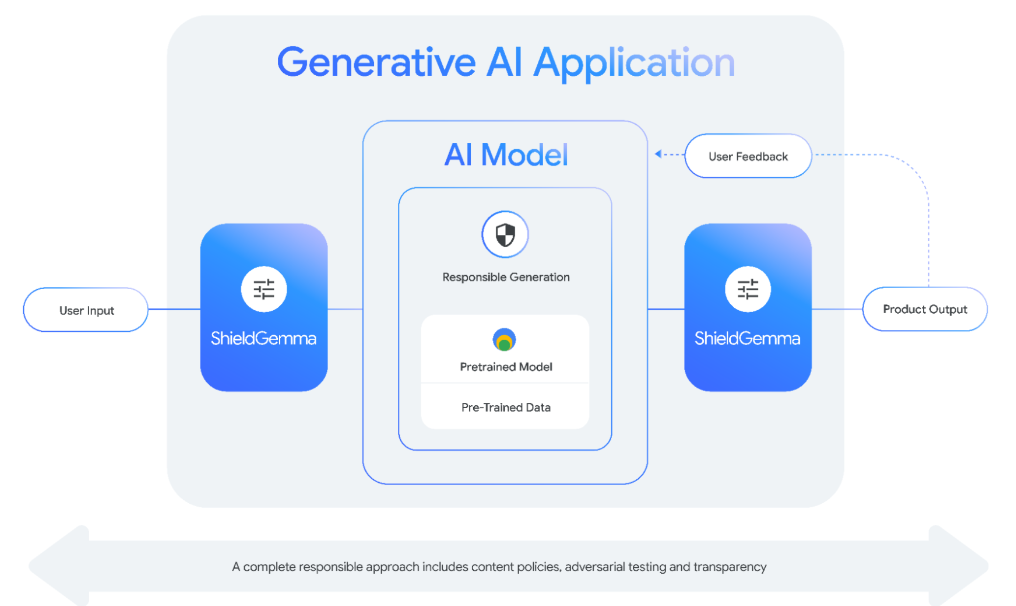
Finalmente, Gemma Scope es un intento de brindar mayor transparencia a los modelos Gemma 2. Lo hace centrándose en partes específicas de los modelos Gemma 2, ayudando a los desarrolladores a interpretar su funcionamiento interno.
«Gemma Scope está formado por redes neuronales especializadas que nos ayudan a empaquetar la información densa y compleja procesada por Gemma 2 y expandirla en una forma que sea más fácil de analizar y comprender», escribió Google en una publicación de blog. «Al estudiar estas vistas ampliadas, los investigadores pueden obtener información valiosa sobre cómo Gemma 2 identifica patrones, procesa información y, en última instancia, hace predicciones».
Gemma 2 2B, ShieldGemma y Gemma Scope ya están disponibles para descargar desde varias fuentes, incluido Hugging Face.
Imagen de portada: SiliconANGLE/Microsoft Designer
Su voto a favor es importante para nosotros y nos ayuda a mantener el contenido GRATIS.
Un clic a continuación respalda nuestra misión de proporcionar contenido gratuito, profundo y relevante.
Únase a nuestra comunidad en YouTube
Únase a la comunidad de más de 15.000 expertos de #CubeAlumni, incluido el director ejecutivo de Amazon.com, Andy Jassy, el fundador y director ejecutivo de Dell Technologies, Michael Dell, el director ejecutivo de Intel, Pat Gelsinger, y muchas más luminarias y expertos.
GRACIAS
Related Posts

Cómo solucionar el error de barba lavanda de Sea Of Thieves

Las 9 mejores computadoras portátiles de 2022: ideales para jugadores y estudiantes
