¿La solución Big Data está en línea? – No teek

Datos dentro del ADN o el mundo dentro de una caja de zapatos
En 2016, una publicación firmada por Thomas Barnet Jr. titulado «La era Zettabyte comienza oficialmente» apareció en el blog de Cisco. qué pasa
La publicación se refería al tráfico global de Internet medido por Cisco, que en 2016 acababa de superar a ZB.1y se espera que supere los 3 ZB para 2021. Pero el tráfico sigue siendo nada comparado con los datos generados (que ya superaron el ZB en 2012), mientras que el IDC, en su informe Fecha Edad 2025 demostró que el límite de 20 ZB ya se ha superado este año y que este crecimiento exponencial llevará a superar los 160 ZB en 2025.

Un barco lleno de datos
Estamos generando una inmensa cantidad de datos y estamos alcanzando rápidamente el límite de la capacidad de la tecnología actual para manejarlos. Algunos pueden argumentar que una gran parte de los datos generados son basura que se puede eliminar fácilmente sin ningún problema, pero es difícil entender hoy qué puede llegar a ser relevante en el futuro, por lo que esto ciertamente no puede considerarse una solución.
Big Data ya es un desafío en términos de capacidad informática hoy en día, pero pronto se convertirá en un desafío en términos de espacio con las tecnologías actuales: los medios SSD han aportado algunas mejoras de rendimiento con respecto a los discos duros magnéticos, pero en lo que respecta al almacenamiento a largo plazo, estamos Todavía pegado con cintas magnéticas.
¿La genética al rescate?
En 2007, GM Skinner, K. Visscher y M. Mansuripur publicaron un artículo bastante innovador en el Journal of Bionanoscience, titulado Escritura biocompatible de datos en el ADN, donde utilizaron un esquema de almacenamiento simple basado en ADN. En este trabajo, el grupo demostró la posibilidad de «escribir» información en líneas de ADN y leerla utilizando un gel específico. El método era aún rudimentario pero el camino estaba allanado.

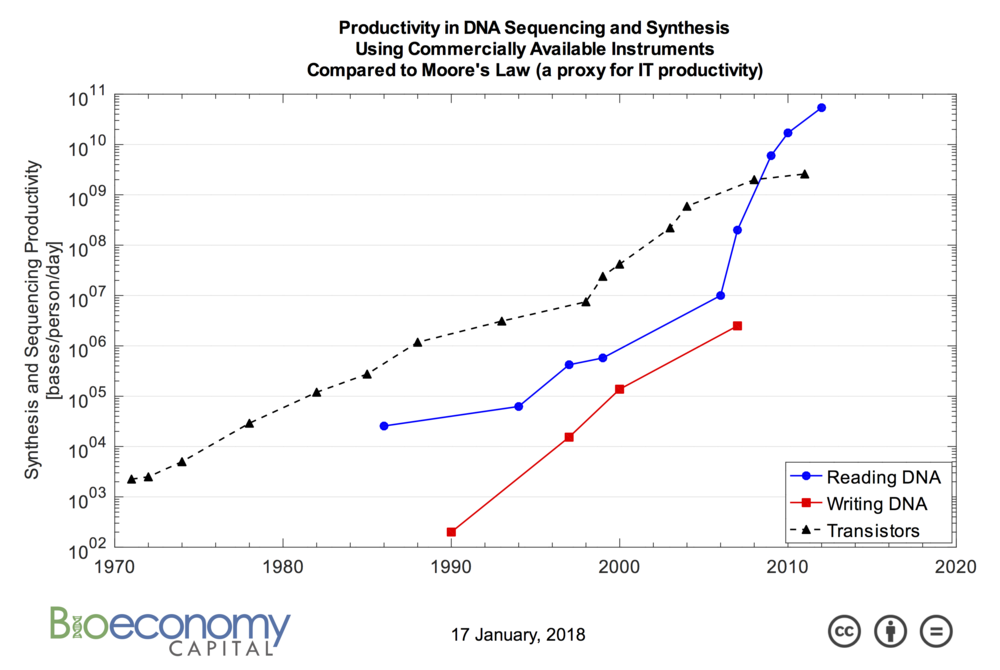
Secuenciación y síntesis
El proceso de lectura del ADN, más conocido como «secuenciación», recibió un gran impulso gracias al trabajo del NHGRI en el marco del Proyecto Genoma Humano, que finalizó en 2003.

El ADN está formado por 4 bases: Afiebre, GRAMOuanine, thimino y citosina. El «truco» es que las únicas combinaciones permitidas son entre Adenina y Timina, y entre Citosina y
¿Por qué ADN?
Hay muchas ventajas:
- Densidad: El ADN es, sobre todo, increíblemente denso. El año pasado ya se superó el límite de 200 PetaBytes (1000 TB) por gramo. Se estima que todos los datos que hay hoy en Internet pueden guardarse fácilmente en el ADN, en el espacio de una caja de zapatos (!).
- Lealtad: la recuperación de datos puede realizarse prácticamente sin errores gracias a la precisión de los métodos de replicación del ADN.
- Sostenibilidad: la energía necesaria para mantener la información codificada en el ADN es una pequeña fracción de la que requieren los centros de datos modernos.
- Longevidad: El ADN es una molécula estable que puede durar miles de años sin degradarse.
Las tecnologías de secuenciación son ahora muy avanzadas, y hoy en día existen incluso secuenciadores de bolsillo USB (ver más abajo), y los dispositivos más avanzados permiten la ejecución de muchas ejecuciones en paralelo.

En cambio, escribir (o sintetizar) ADN requiere «pegar» una base tras otra en un ambiente controlado, un proceso químico muy lento que se remonta a 1981. Sin embargo, debido a la enorme demanda del mercado, hay empresas como Twist Bioscience y DNA Script que han desarrollado tecnologías de síntesis innovadoras, basadas respectivamente en silicio y síntesis enzimática, que prometen volúmenes órdenes de magnitud superiores a los tradicionales. Además, recientemente, dos investigadores del departamento de Informática de Biología Sintética del JBEI presentaron una nueva metodología de síntesis que podría conducir a la creación de impresoras 3D de ADN.
Desde el trabajo de Skinner & coll. La investigación ha logrado grandes avances: en 2015, microsoft y MISL de la Universidad de Washington crearon el proyecto DNA Storage, que estableció un récord en 2016 al almacenar y recuperar con éxito 200 MB en cadenas de ADN. En 2017, en otro importante trabajo, Y. Erlich y D. Zielinski, almacenaron y recuperaron 2 MB de material con una densidad de más de 200 PetaByte por gramo, rozando el límite teórico postulado por Shannon, mediante el uso de «códigos fuente». «.

A día de hoy, el proceso de síntesis/secuenciación del ADN sigue siendo muy caro (estamos hablando de unos miles de dólares por MB por escritura y 200 por lectura) pero se espera que disminuya, tanto por la rápida evolución del sector, como por la explosiva demanda de ADN modificado, tanto porque para el almacenamiento de datos es posible utilizar ADN sintetizado ad hoc en lugar del biológico. En este sentido, se espera que el uso extensivo de tecnologías de edición como CRISPR/Cas9, TALEN
Aplicaciones
El uso del ADN para la digitalización no es, por tanto, algo que pertenezca a la ciencia ficción, pero ya estamos empezando a ver los primeros prototipos de aplicación.
- Cifrado:
Carverr Una startup estadounidense ha desarrollado un método para codificar datos en moléculas de ADN y ofrece un servicio de cifrado de contraseñas basado en ADN por 1.000 dólares. - Una nube: en marzo pasado Microsoft publicó un artículo sobre Nature donde demostraba la capacidad de realizar lecturas de ADN.
aleatorio acceso, aumentando dramáticamente la eficiencia del proceso de secuenciación. Gracias a avances como este y los mencionados anteriormente, Microsoft parece estar empezando a considerar el ADN para la copia de seguridad en la nube en el futuro y está colaborando activamente con Twist Biosciences. Los costes siguen siendo muy elevados, pero los habitantes de Redmond están convencidos de que este obstáculo se superará fácilmente si hay suficiente demanda por parte de la industria informática.
Nota
Un zettabyte equivale aproximadamente a mil millones de terabytes (TB). Si consideramos que 1 TB es aproximadamente el tamaño de un disco duro promedio hoy en día, es fácil darse cuenta del tamaño de este tráfico.
Un código fuente es una forma de tomar datos (por ejemplo, un archivo) y transformarlos en un número prácticamente ilimitado de fragmentos codificados, de modo que el archivo original pueda volver a ensamblarse a partir de cualquier conjunto de esos fragmentos, siempre que el total sea ligeramente mayor que el tamaño original. Lo que hace que este tipo de algoritmo sea notable es que le permite enviar información a través de canales «ruidosos» sin necesidad de que el receptor envíe comentarios sobre los paquetes faltantes. Es decir, tener un archivo de 10 MB, para el destinatario será suficiente para
Con Acceso aleatorio En TI nos referimos a la capacidad de acceder a cualquier ubicación de medios sin tener que pasar por ubicaciones anteriores (acceso serie).
Enlaces
Cronología interactiva del genoma humano
Wikipedia: almacenamiento digital de ADN
Almacenamiento
LA PARTE INFERIOR DEL ALMACÉN DE DATOS DE ADN
Acceso aleatorio en almacenamiento de datos de ADN a gran escala.
El almacenamiento de datos de ADN está más cerca de convertirse en una realidad
Investigadores de Microsoft y la Universidad de Washington han establecido un récord en almacenamiento de ADN
Cómo el ADN puede almacenar todos los datos del mundo
El almacenamiento de datos en el ADN lleva la naturaleza al universo digital
Hacia el almacenamiento práctico de información digital en ADN sintetizado de alta capacidad y bajo mantenimiento (pdf)
Almacenamiento de ADN: un nuevo método para almacenar información digital
¿El ADN sintético expulsará del mercado a Ledger y Trezor?
Síntesis y secuenciación
EXTRACCIÓN DE ADN CON UNA CENTRÍFUGA IMPRESA EN 3D
INGENIERÍA INVERSA DE UN SECUENCIADOR DE ADN
Una nueva investigación podría conducir a una impresora de ADN 3D
DNA Fountain permite una arquitectura de almacenamiento robusta y eficiente (pdf)
MinION: Un secuenciador de ADN completo en una memoria USB
Mercado de secuenciadores de ADN: industrias emergentes, potencial de ingresos, análisis de la estructura de costos y actores clave
Aplicaciones
Los fanáticos de Bitcoin están almacenando sus contraseñas de criptomonedas en el ADN
La impresión 3D podría ser la clave para un almacenamiento de datos asequible utilizando ADN
Malditos algoritmos geniales: códigos fuente
Andrea ha trabajado en TI durante casi 20 años, cubriendo todo, desde desarrollo hasta análisis de negocios y gestión de proyectos.
Hoy podemos decir que es un gnomo desenfadado, apasionado de las Neurociencias, la Inteligencia Artificial y la fotografía.
Related Posts

Comprensión de la responsabilidad en accidentes de vehículos de 18 ruedas: cómo un abogado de San Antonio puede responsabilizar a las partes negligentes
